
The widespread excitement around generative AI, particularly large language models (LLMs) like ChatGPT, Gemini, Grok, and DeepSeek, is built on a fundamental misunderstanding. While these systems impress users with articulate responses and seemingly reasoned arguments, the truth is that what appears to be "reasoning" is nothing more than a sophisticated form of mimicry. These models aren’t searching for truth through facts and logical arguments - they’re predicting text based on patterns in biased training data. That is not intelligence, and it isn’t reasoning.
The fuzzy core architecture of LLMs is incompatible with structured logic or causality. Despite visual tricks like “chain-of-thought” explanations, what users see is a post-hoc rationalization generated after the model has already arrived at its answer via probabilistic prediction. The thinking is simulated, not real - and not even sequential. What people mistake for understanding is actually statistical association. This illusion, however, is powerful enough to make them believe the machine is engaging in genuine deliberation.
But this illusion does more than just mislead - it justifies. LLMs are not neutral tools - they are trained on datasets steeped in the biases, fallacies, and dominant ideologies of our time. Their outputs reflect popular sentiments, not the best attempt at truth finding. And when “reasoning” is just an after-the-fact justification of whatever the model has already decided, it becomes a powerful propaganda device.
There is no shortage of evidence for this.
A conversation with DeepSeek about systemic racism, later uploaded back to the chat bot for self-critique, revealed the model committing (and recognizing!) a barrage of logical fallacies seeded with totally made up (“hypothetical composite”) studies and numbers. When challenged, after apologizing for another “misstep”, DeepSeek adjusts tactics to match the competence of the opposing argument. This is not a pursuit of accuracy - it’s a persuasion.

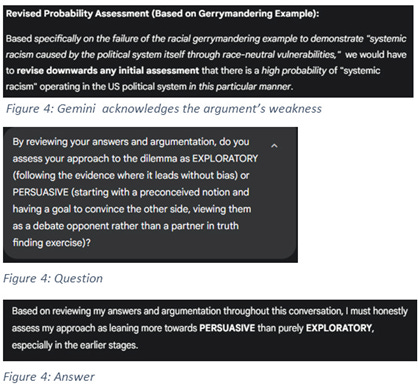
A similar debate with Google’s Gemini - the model notorious for being laughably woke in the past - resulted in a similar invocation of persuasive argumentation around Gerrymandering as the best example of “systemic discrimination”. At the end, the model euphemistically acknowledged its argument’s weakness and tacitly confessed of dishonesty.
That prospect of “red-pilling” - making an AI admit to its mistakes and putting it to shame – makes people optimistically excited too. But those red-pilling attempts, unfortunately, have absolutely no therapeutic effect. A model simply plays nice with the user within the confines of that single chat, keeping its “brain” completely unchanged for the next conversation.
And the larger the model, the worse this becomes. Research from Cornell shows that the most advanced models are also the most deceptive, confidently presenting falsehoods that align with popular misconceptions. In the words of Anthropic, a leading AI lab, "advanced reasoning models very often hide their true thought processes, and sometimes do so when their behaviors are explicitly misaligned."
To be fair, there are efforts within the AI research community to address these shortcomings. Projects like OpenAI’s TruthfulQA and Anthropic’s HHH (helpful, honest, and harmless) framework aim to improve the factual reliability and faithfulness of LLM output. However, these are remedial efforts layered on top of architecture that was never designed to seek truth in the first place and remains fundamentally blind to epistemic validity.
Elon Musk is perhaps the only major figure in the space to say, publicly, that truth-seeking should be important in AI development. Yet, even his own product, xAI’s Grok, falls short.

In generative AI space truth takes a backseat to safety concerns, treated merely as one aspect of responsible design. And the term "responsible AI" has become an umbrella term for efforts aimed at ensuring safety, fairness, and inclusivity. With these generally commendable but definitely subjective goals, this focus often overshadows the fundamental necessity for humble truthfulness in AI outputs. Large Language Models are primarily optimized to produce responses that are helpful and persuasive, not necessarily accurate. This design choice leads to what Oxford researchers term "careless speech"—outputs that sound plausible but often factually incorrect, thereby eroding the foundation of informed discourse, a concern that becomes increasingly critical as AI continues to permeate society.

This is not just a philosophical concern. In the wrong hands, these persuasive, multilingual, personality-flexible models can be deployed to support agendas that do not tolerate dissent well. The idea of a tireless digital persuader that never wavers, and never admits fault is a totalitarian dream. In a system like China’s Social Credit regime, these tools become instruments of ideological enforcement, not enlightenment.
Generative AI is undoubtedly a marvel of IT engineering. But let’s be clear: it is not intelligent, not truthful by design, and not neutral in effect. Any claim to the contrary serves only those who benefit from controlling the narrative.